Part 4 Appendices
4.1 Conceptual framework
4.1.1 Adaptive assessment
A test in which the candidates have to perform assignments of varying difficulty depending on the candidate’s competence, which is estimated based on previous items.
An IRT-based adaptive assessment involves calibrated items that can be assessed most accurately at a given level of competence of the candidates. In the case of a computer-based adaptive assessment, items will no longer be offered to the candidate once the level of competence has been determined at the desired level of accuracy. See also: item response theory.
4.1.2 Playback environment
The component of a test system in which assessments and items are offered to the candidates and the responses are recorded.
- ensures that students can take the test after logging in;
- is often combined with a secure browser, which ensures that students cannot use unauthorised software to search the Internet, communicate with third parties, etc.;
- records the responses and sends them back to the item bank.
4.1.4 Reliability
The extent to which the score obtained on an assessment does not depend on chance. The extent to which an assessment yields the same result under identical conditions. In statistical terms, reliability is described in terms of the extent to which a measurement is free from measurement errors (also known as noise or error). See also: misclassifications.
4.1.5 Body of Knowledge (BoK)
A Body of Knowledge (BoK) is a common knowledge base for a field of study or discipline from which a professional practitioner derives their theoretical and practical knowledge, insights and methods. This concerns not just theory, but also the proven insights and methods of the profession in question.
4.1.6 Businesscase
A business case or a feasibility study describes the decision to either launch or discontinue a project or task. A business case weighs the costs against the benefits and considers the attendant risks. A business case does not intend to make any financial assessment. A good business case will explicitly also include considerations relating to quality. Aspects such as quality improvement can be very important for an institution, while the purely financial gain can be difficult to pinpoint. See also the whitepaper De businesscase van digitaal toetsen.
4.1.7 Cronbach’s alpha
A psychometric measure used for non-repeated assessments (i.e. a one-off assessment such as an examination) that reflects the extent to which the measurement is subject to measurement errors. Cronbach’s alpha is suitable for polytomous scored items. Questions to which, in addition to correct-incorrect (0 or 1), points can also be given, for example 0, 1, 2, 3, etc. See also: KR20.
4.1.8 Diagnostic assessments (a subset of formative assessment)
A formative assessment in which a candidate gains insight into their progress through the subject matter. A diagnostic assessment is representative in terms of content and level, possibly followed by a final summative assessment. See also: practice assessments.
4.1.9 Digital assessment system
This is the cyclical process of implementing and continuously improving an assessment process, starting from the learning objectives and including test items, assessment, exam administration and analysis. The development and management of the item bank is often located at the centre of this cycle.

Figure 4.1: Components digital assessment systems portrayed on the assessment cycle.
4.1.10 Formative feedback
Feedback in which the benefit for the learning process is paramount. Feedback is intended to encourage students to deepen their knowledge of the subject matter. When an incorrect response is given, instructions are often given on how to ascertain the correct answer or else the correct response is simply provided. If the responses are correct, in-depth resources can be provided or another example is sometimes discussed.
4.1.11 Formative assessment
Assessment in which learning for the exam is paramount. Based on the literature, it is recommended that you do not follow the practice of giving grades. The learning process benefits from taking test assignments and learning from your mistakes. No effort is made to achieve a certain minimum level. Sometimes also referred to as Assessment for Learning or Assessment as Learning.
4.1.12 Parameterised question
An item consisting of a fixed main structure plus some variable elements (numbers, objects, concepts, principles), so that they constitute a new item each time. Some item bank systems generate a unique new item for the lecturer or a unique set of values for each student each time.
4.1.13 IMS
An IMS standard is established by the IMS Global Learning Consortium, a community of higher education institutions, suppliers and government institutions that jointly develop standards to ensure interoperability. When IMS started out back in 1997, its official name was the Instructional Management Systems (IMS) project.
4.1.14 Item response theory (IRT)
Item response theory (IRT) is a method based on the assumption that the probability of a candidate correctly answering an item is determined by the candidate’s skill as a function of the difficulty level of the item and the distinctiveness of the item. IRT is a theory based on the attributes of the items, while classical test theory is based on the attributes of an exam. Before you can deploy IRT in a meaningful way, these attributes must be established prior to an assessment based on a large number of administered tests among a population in which all skills levels are represented (known as calibration). See also: adaptive assessment.
4.1.15 Item
An assignment/task in which the candidate must give the correct response. Also referred to as a question, test question or test item.
4.1.16 Item bank
A collection of items for a specific test objective. An item bank has a certain structure, usually hierarchical and based on metadata.
4.1.17 Item bank system
Software used for storing and editing item banks. Item bank systems may be separate systems or may be part of an assessment system. An assessment system will also include features to help you create assessments, administer tests, score them and carry out test analyses.
4.1.18 Classical test theory
The basic assumption of classical test theory (CTT) is that the score observed in a test will consist of the actual score plus a measurement error. Values such as Cronbach’s alpha, which is an estimate of the magnitude of the measurement error, can be calculated as a function of these fundamental assumptions.
4.1.19 KR20
A psychometric measure used for non-repeated assessments (i.e. a one-off assessment such as an examination) that reflects the extent to which the measurement is subject to measurement errors. The only difference between KR20 and Cronbach’s alpha is that only dichotomous scored items, such as multiple-choice questions, can be counted in KR20. Items that are correct or incorrect and will return 0 or 1 point. See also: Cronbach’s alpha.
4.1.20 Learning analytics
Learning analytics is the collection and analysis of educational data generated by students while learning online. The educational data will be converted into valuable information and can help to improve the quality of teaching. See also: https://www.surf.nl/en/expertises/learning-analytics.
4.1.21 LTI
LTI (the Learning Tools Interoperability standard) is an IMS standard that facilitates the linking of assessment systems to other systems, such as learning management systems (such as Blackboard or Canvas). Lecturer and student data is automatically exchanged between the systems, assessments can be initiated from the LMS, and the test scores are fed back to the grading functions of the LMS. See also: SCORM.
4.1.22 Measurement error
The measurement error in an assessment is the deviation from the score obtained on a test that cannot be explained. The actual score is the observed score less the measurement error.
4.1.23 Metadata
Data added to items to describe additional attributes. This data can be used to structure the items (see: structure), search, filter and select.
4.1.24 Misclassifications
The proportion of candidates who have either wrongly failed or passed an assessment. Assessments with a low degree of reliability have a high degree of misclassification. See also: reliability.
4.1.25 Practice assessments (a subset of formative assessments)
An assessment in which a candidate can practice dealing with the subject matter. The candidate can choose the topics and level themselves. These tests are often used to practice dealing with concepts or ideas, especially if these are particularly difficult. Some adaptivity is sometimes built in so that the playback environment offers items to candidates at the most appropriate level. See also: diagnostic assessment.
4.1.26 Psychometric data
Psychometric data refers to the data that is calculated from assessments that are administered and items that are indicative of the quality of the assessment. On the one hand, they are indicative of the reliability and the level of difficulty of assessments as a whole. Yet they are also indicative of the distinctiveness and the level of difficulty of individual items in those tests. See also: classical test theory, item response theory, Cronbach’s alpha, P-value, Rit value.
4.1.27 P-value
The proportion of candidates who answered an item correctly. Also called the level of difficulty of an item. The higher the P-value, the easier the item is. The P-value is only used in classical test theory.
4.1.28 QTI
QTI (Question and Test Interoperability) is an IMS standard for the interoperability of items and tests between assessment systems.
4.1.29 Rit-value
The correlation between the score of the candidates on the item and the score on the test as a whole less the specific item in question. The Rir-value is a somewhat stricter measure of the distinctive capacity than the Rit-value because the Rir-value excludes the influence of the item itself on distinctive capacity. The Rir-value is only used in classical test theory. See also: Rit-value and classical test theory.
4.1.30 SCORM
SCORM (Sharable Content Object Reference Model) is an IMS standard that facilitates the linking of assessment systems to other systems, such as learning management systems (like Blackboard or Canvas). Lecturer and student data, in particular, is automatically exchanged between the systems, assessments can be initiated from the LMS, and the test scores are fed back to the grading functions of the LMS. See also: LTI.
4.1.31 Stable domain
A field of study that is subject to little change. See also: volatile domain.
4.1.32 Structure
The way in which a collection of items is logically ordered, for example, in a tree structure.
4.1.33 Summative assessment
Testing that focuses on measuring a certain level of competence as accurately as possible. The score obtained on an assessment of this type is used in the formal allocation of a study achievement, such as credits or a certificate. For example, following an exam. Sometimes also referred to as assessment or learning.
4.1.34 Test item
See: item.
4.1.35 Test transparancy
The entirety of aspects relating to assessment, including the degree of transparency, reliability and validity of the assessment. For instance, transparency can increase if insight is available into how items are created; reliability can increase where items are better at differentiating between students with differing degrees of competence in the subject matter or skill; validity can increase as the items better and more fully measure the intended knowledge or skill.
4.1.36 Test matrix
A test matrix is a table showing how test assignments in a given test are distributed over the subject matter. The desired type of skill, such as knowledge, understanding or application, will often also be shown for each component of the subject matter. Sometimes also referred to as a test plan, specification table or blueprint.
4.1.37 Test safety
The extent to which candidates provide correct responses to items and tests in a way which is compliant with the regulations (no fraud). For instance, because items have been stolen or have ended up in the public domain, or because candidates have access to unauthorised resources during the assessment, or because candidates can tamper with test results. See SURF’s publication Secure Assessment Workbook.
4.1.38 Test question
See: [#item].
4.1.39 Field of study
A field of study is a field of professional knowledge and competencies in which people can specialise. The sharing of experiences and professional knowledge usually requires a specialist vocabulary.
4.1.40 Question database
A system in which all items have been collected.
4.1.41 Volatile domain
A field of study that is subject to many changes due to newly developing knowledge, methods or technologies. See also: stable domain.
4.1.42 Workflow
A logical, fixed sequence of activities to be performed to obtain a predefined outcome. These steps may be sequential, but may also be carried out in parallel depending on the purpose of the process.
4.2 Item development workflows
This appendix describes three practical examples of item development workflows.
4.2.1 An item development process by two lecturers
A coordinator/examiner from the Faculty of Earth and Life Sciences at VU Amsterdam develops and maintains an item bank on the subject of Microbiology. Approximately 60 new items are created each year.
- The coordinator started the item bank based on the item bank of McGrawHill: Prescott’s Microbiology. The structure of the item bank follows the chapters from that book. The item bank is supplied by the publisher in Word format. The lecturer copies the items one by one to the online item bank system: QMLive.
- The coordinator performs a quality check during data entry: about 80-90 percent of the items are relevant and of good quality. The coordinator deletes the rest of the items.
- The lecturer first creates a new item in MS Word.
- One week before the course component is taught, the coordinator will invite the lecturer who will be teaching to review new items. The review is carried out in MS Word.
- The coordinator will modify the item based on the feedback from the lecturer. He or she then enters it into the item bank system.
- Following the test and based on the psychometric analysis, the lecturer will modify an item for future use directly in the item bank.
It will take the lecturer about half an hour – excluding feedback – to develop a good-quality item. The coordinator will primarily create questions of any type, often with images, except multiple-choice questions. The time per item is relatively long.
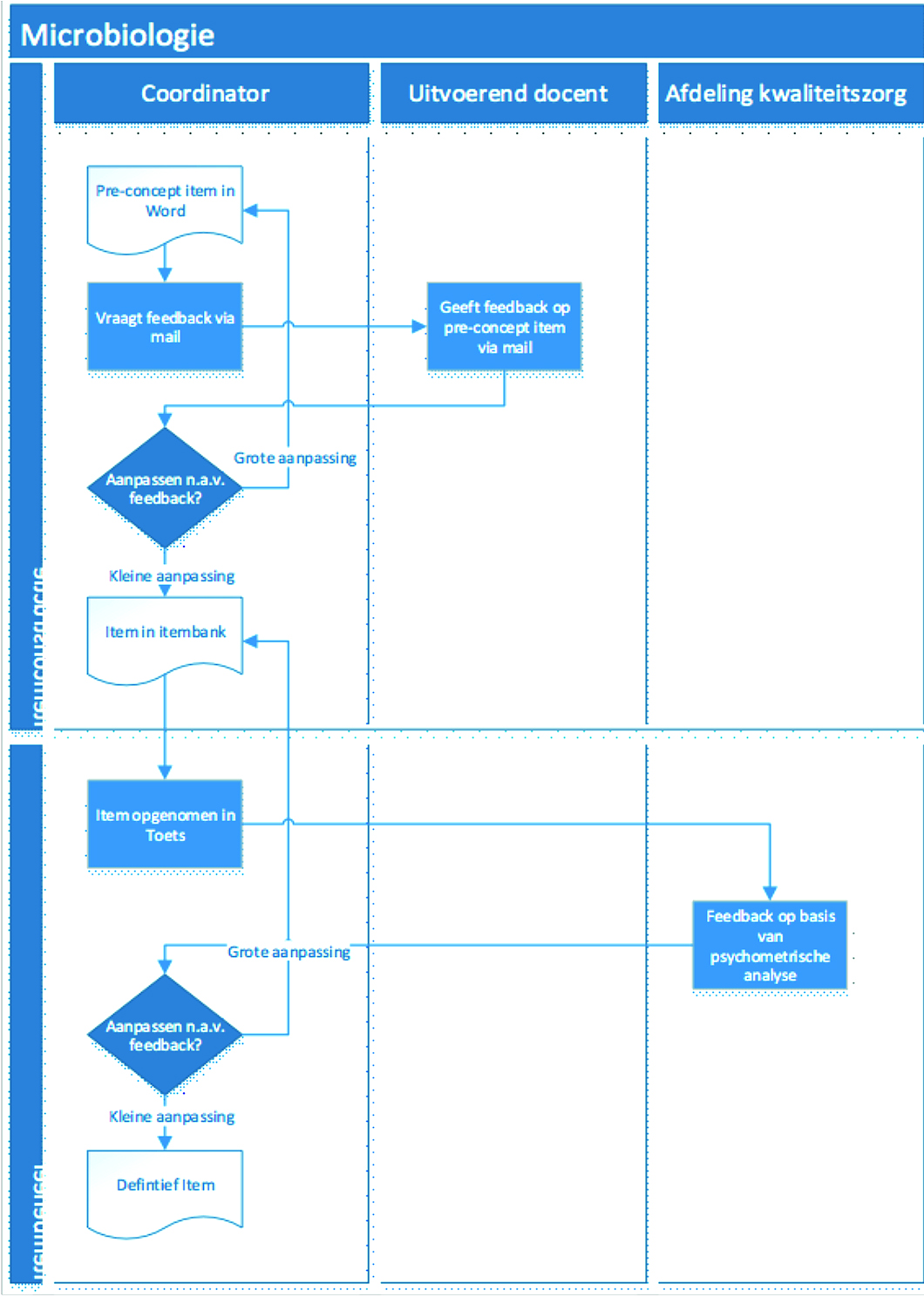
Figure 4.2: Itembank workflow 1.
4.2.2 Item development process with collaboration between universities of applied sciences
Toets & Leer was a collaborative venture between six universities of applied sciences (2012 – 2018) involving item banks for the subjects of Business Administration/Accounting, Business Economics, Tax Law, Marketing, Management and Law.
The participating institutions provided lecturers to develop the items. They provided their time in kind. On an annual basis, they delivered 300 items per institution. The work process was as follows:
- A lecturer develops an item and then enters it into the item bank system. The lecturer informs a fellow lecturer from one of the other institutions, usually per group of items.
- The fellow lecturer checks the items and makes any changes or additions that may be needed. Any additions and comments are stored in the assessment application. The reviewing lecturer then notifies the original author, who then reviews the changes.
- The item is subject to testing by an external agency. If necessary, the original author receives comments or a change request. This is followed by a new check.
- The item in the assessment application receives final approval.
- Occasionally, feedback will be based on a psychometric analysis. In an ideal scenario, the process will include an editor. In this case, it took about half an hour on average to develop a good-quality item including feedback. Most items were multiple-choice questions (about 80 percent) and cloze test questions (short text or number, about 20 percent).
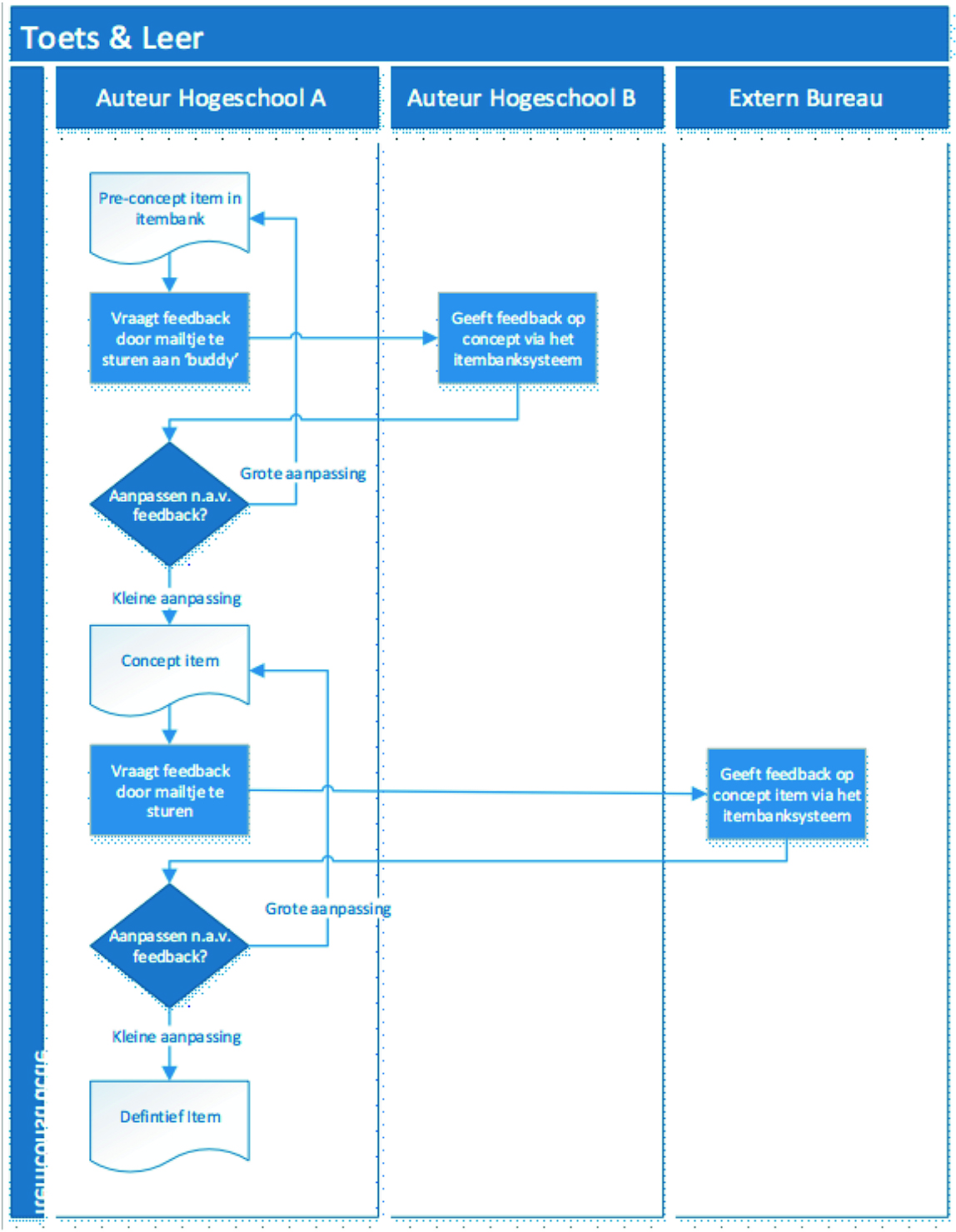
Figure 4.3: Itembank workflow 2.
4.2.3 Item development process for MBO Knowledge Test Bank
The vocational education and training schools involved provide lecturers to develop the items. Item developers are paid for four hours of item development per week. About six to ten item developers are active per item bank.
- The item developers work in a team to construct rough draft items with feedback, arranged according to both the qualification dossier and the Body of Knowledge (BoK). These rough draft items are circulated among multiple lecturers several times (internal validation). Labels on items clearly show which items still need to be viewed (meta tags). Additions and comments are tracked in the item bank system.
- Monthly face-to-face working sessions are held with assessment experts and lecturers from the participating schools. In these sessions, the teams will discuss new items for each qualification dossier. The resulting items are drafts.
- The item developer then modifies the draft items if needed. The resulting items are then ready for publication. Language editing will take place prior to publication.
- Modification is an ongoing process. Users can comment on items, and this may lead to more modifications. If major modifications are made, it is possible to resubmit the items for renewed internal and external validation.
- Feedback in the item bank project is only provided occasionally and is based on a psychometric analysis.
On average, it will take about 1 hour – including feedback – to develop a good-quality item.
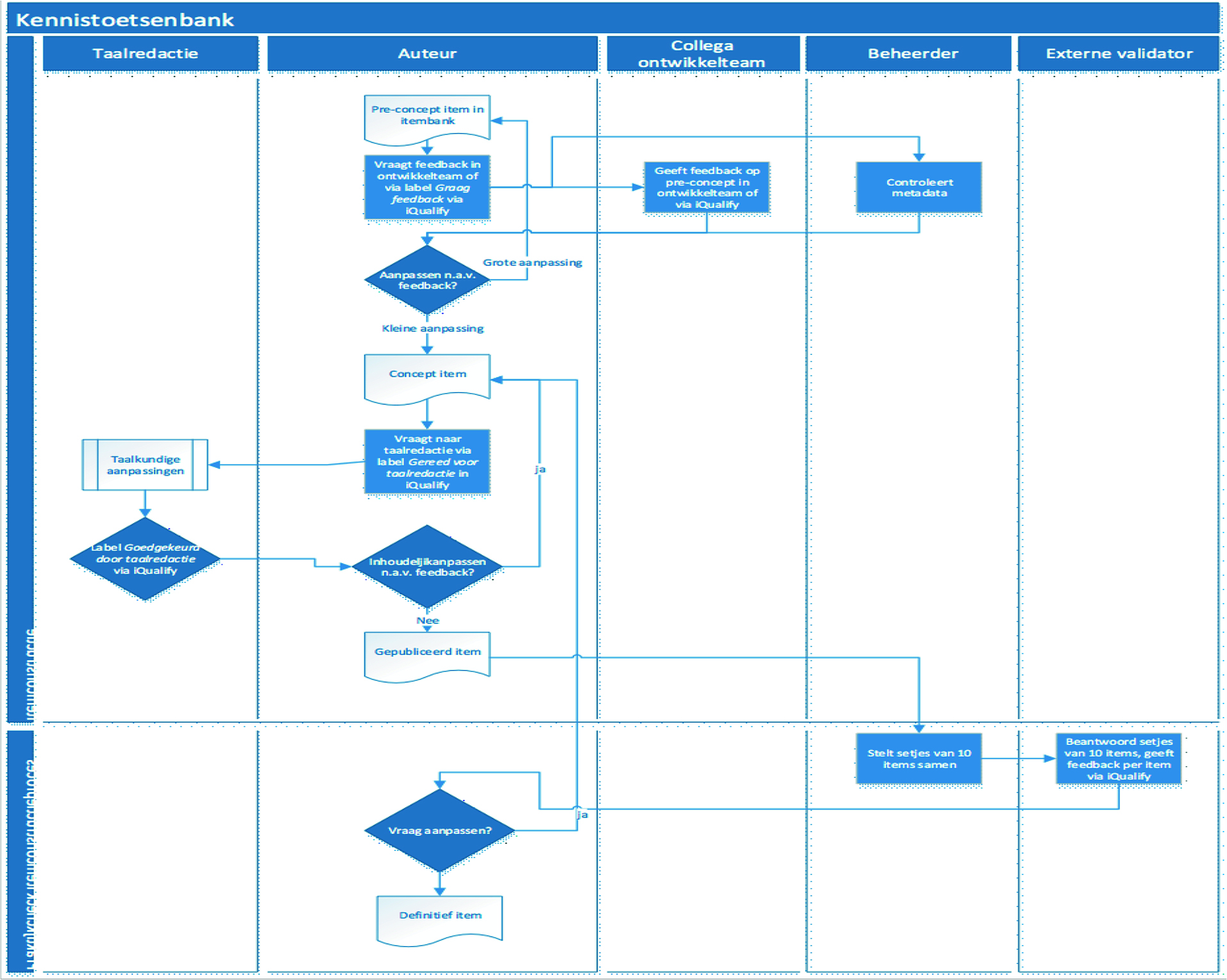
Figure 4.4: Itembank workflow 3.